在爬虫工作中将起到重要的作用,但是从成本的角度来说,一般稳定的ip池都很贵,因此我这个开源项目的意义就诞生了,爬取一些代理网站提供的免费ip(虽然70%都是不好使的,但是扛不住量大,网站多),检测有效性后存储到数据库中,同时搭建一个http服务器,提供一个api接口,供大家的爬虫程序调用。
好了,废话不多说,咱们进入今天的主题,讲解一下我写的这个开源项目IPProxys。
下面是这个项目的工程结构:
api包:主要是实现http服务器,提供api接口(通过get请求,返回json数据)
data文件夹:主要是数据库文件的存储位置和qqwry.dat(可以查询ip的地理位置)
db包:主要是封装了一些数据库的操作
spider包:主要是爬虫的核心功能,爬取代理网站上的代理ip
test包:测试一些用例,不参与整个项目的运行
util包:提供一些工具类。IPAddress.py查询ip的地理位置
validator包:用来测试ip地址是否可用
config.py:主要是配置信息(包括配置ip地址的解析方式和数据库的配置)
接下来讲一下关键代码:
首先说一下apiServer.py:
#coding:utf-8
'''
定义几个关键字,count types,protocol,country,area,
'''
import urllib
from config import API_PORT
from db.SQLiteHelper import SqliteHelper
__author__ = 'Xaxdus'
import BaseHTTPServer
import json
import urlparse
# keylist=['count', 'types','protocol','country','area']
class WebRequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
def do_GET(self):
"""
"""
dict={}
parsed_path = urlparse.urlparse(self.path)
try:
query = urllib.unquote(parsed_path.query)
print query
if query.find('&')!=-1:
params = query.split('&')
for param in params:
dict[param.split('=')[0]]=param.split('=')[1]
else:
dict[query.split('=')[0]]=query.split('=')[1]
str_count=''
conditions=[]
for key in dict:
if key =='count':
str_count = 'lIMIT 0,%s'% dict[key]
if key =='country' or key =='area':
conditions .append(key+" LIKE '"+dict[key]+"%'")
elif key =='types' or key =='protocol' or key =='country' or key =='area':
conditions .append(key+"="+dict[key])
if len(conditions)>1:
conditions = ' AND '.join(conditions)
else:
conditions =conditions[0]
sqlHelper = SqliteHelper()
result = sqlHelper.select(sqlHelper.tableName,conditions,str_count)
# print type(result)
# for r in result:
# print r
print result
data = json.dumps(result)
self.send_response(200)
self.end_headers()
self.wfile.write(data)
except Exception,e:
print e
self.send_response(404)
if __name__=='__main__':
server = BaseHTTPServer.HTTPServer(('0.0.0.0',API_PORT), WebRequestHandler)
server.serve_forever()
从代码中可以看出是对参数的解析,参数包括 count(数量), types(模式),protocol(协议),country(国家),area(地区),(
types类型(0高匿名,1透明),protocol(0 http,1 https http),country(国家),area(省市))
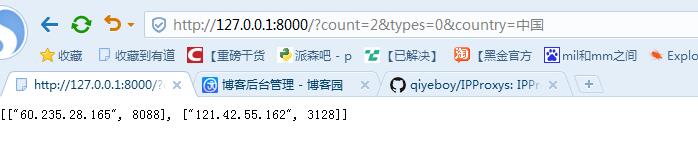
例如访问http://127.0.0.1:8000/?count=8&types=0.返回json数据。如下图所示:

接着说一下SQLiteHelper.py(主要是对sqlite的操作):
#coding:utf-8
from config import DB_CONFIG
from db.SqlHelper import SqlHelper
__author__ = 'Xaxdus'
import sqlite3
class SqliteHelper(SqlHelper):
tableName='proxys'
def __init__(self):
'''
建立数据库的链接
:return:
'''
self.database = sqlite3.connect(DB_CONFIG['dbPath'],check_same_thread=False)
self.cursor = self.database.cursor()
#创建表结构
self.createTable()
def createTable(self):
self.cursor.execute("create TABLE IF NOT EXISTS %s (id INTEGER PRIMARY KEY ,ip VARCHAR(16) NOT NULL,"
"port INTEGER NOT NULL ,types INTEGER NOT NULL ,protocol INTEGER NOT NULL DEFAULT 0,"
"country VARCHAR (20) NOT NULL,area VARCHAR (20) NOT NULL,updatetime TimeStamp NOT NULL DEFAULT (datetime('now','localtime')) ,speed DECIMAL(3,2) NOT NULL DEFAULT 100)"% self.tableName)
self.database.commit()
def select(self,tableName,condition,count):
'''
:param tableName: 表名
:param condition: 条件包含占位符
:param value: 占位符所对应的值(主要是为了防注入)
:return:
'''
command = 'SELECT DISTINCT ip,port FROM %s WHERE %s ORDER BY speed ASC %s '%(tableName,condition,count)
self.cursor.execute(command)
result = self.cursor.fetchall()
return result
def selectAll(self):
self.cursor.execute('SELECT DISTINCT ip,port FROM %s ORDER BY speed ASC '%self.tableName)
result = self.cursor.fetchall()
return result
def selectCount(self):
self.cursor.execute('SELECT COUNT( DISTINCT ip) FROM %s'%self.tableName)
count = self.cursor.fetchone()
return count
def selectOne(self,tableName,condition,value):
'''
:param tableName: 表名
:param condition: 条件包含占位符
:param value: 占位符所对应的值(主要是为了防注入)
:return:
'''
self.cursor.execute('SELECT DISTINCT ip,port FROM %s WHERE %s ORDER BY speed ASC'%(tableName,condition),value)
result = self.cursor.fetchone()
return result
def update(self,tableName,condition,value):
self.cursor.execute('UPDATE %s %s'%(tableName,condition),value)
self.database.commit()
def delete(self,tableName,condition):
'''
:param tableName: 表名
:param condition: 条件
:return:
'''
deleCommand = 'DELETE FROM %s WHERE %s'%(tableName,condition)
# print deleCommand
self.cursor.execute(deleCommand)
self.commit()
def commit(self):
self.database.commit()
def insert(self,tableName,value):
proxy = [value['ip'],value['port'],value['type'],value['protocol'],value['country'],value['area'],value['speed']]
# print proxy
self.cursor.execute("INSERT INTO %s (ip,port,types,protocol,country,area,speed)VALUES (?,?,?,?,?,?,?)"% tableName
,proxy)
def batch_insert(self,tableName,values):
for value in values:
if value!=None:
self.insert(self.tableName,value)
self.database.commit()
def close(self):
self.cursor.close()
self.database.close()
if __name__=="__main__":
s = SqliteHelper()
print s.selectCount()[0]
# print s.selectAll()
HtmlPraser.py(主要是对html进行解析):
使用lxml的xpath进行解析
#coding:utf-8
import datetime
from config import QQWRY_PATH, CHINA_AREA
from util.IPAddress import IPAddresss
from util.logger import logger
__author__ = 'Xaxdus'
from lxml import etree
class Html_Parser(object):
def __init__(self):
self.ips = IPAddresss(QQWRY_PATH)
def parse(self,response,parser):
'''
:param response: 响应
:param type: 解析方式
:return:
'''
if parser['type']=='xpath':
proxylist=[]
root = etree.HTML(response)
proxys = root.xpath(parser['pattern'])
for proxy in proxys:
# print parser['postion']['ip']
ip = proxy.xpath(parser['postion']['ip'])[0].text
port = proxy.xpath(parser['postion']['port'])[0].text
type = proxy.xpath(parser['postion']['type'])[0].text
if type.find(u'高匿')!=-1:
type = 0
else:
type = 1
protocol=''
if len(parser['postion']['protocol']) > 0:
protocol = proxy.xpath(parser['postion']['protocol'])[0].text
if protocol.lower().find('https')!=-1:
protocol = 1
else:
protocol = 0
else:
protocol = 0
addr = self.ips.getIpAddr(self.ips.str2ip(ip))
country = ''
area = ''
if addr.find(u'省')!=-1 or self.AuthCountry(addr):
country = u'中国'
area = addr
else:
country = addr
area = ''
# updatetime = datetime.datetime.now()
# ip,端口,类型(0高匿名,1透明),protocol(0 http,1 https http),country(国家),area(省市),updatetime(更新时间)
# proxy ={'ip':ip,'port':int(port),'type':int(type),'protocol':int(protocol),'country':country,'area':area,'updatetime':updatetime,'speed':100}
proxy ={'ip':ip,'port':int(port),'type':int(type),'protocol':int(protocol),'country':country,'area':area,'speed':100}
print proxy
proxylist.append(proxy)
return proxylist
def AuthCountry(self,addr):
'''
用来判断地址是哪个国家的
:param addr:
:return:
'''
for area in CHINA_AREA:
if addr.find(area)!=-1:
return True
return False
IPAddresss.py(通过读取纯真qqwry.dat,对ip地址进行定位),读取的方式可以参考:http://ju.outofmemory.cn/entry/85998;https://linuxtoy.org/archives/python-ip.html
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import socket
import struct
class IPAddresss:
def __init__(self, ipdbFile):
self.ipdb = open(ipdbFile, "rb")
str = self.ipdb.read(8)
(self.firstIndex, self.lastIndex) = struct.unpack('II', str)
self.indexCount = (self.lastIndex - self.firstIndex)/7+1
# print self.getVersion(), u" 纪录总数: %d 条 "%(self.indexCount)
def getVersion(self):
s = self.getIpAddr(0xffffff00L)
return s
def getAreaAddr(self, offset=0):
if offset:
self.ipdb.seek(offset)
str = self.ipdb.read(1)
(byte,) = struct.unpack('B', str)
if byte == 0x01 or byte == 0x02:
p = self.getLong3()
if p:
return self.getString(p)
else:
return ""
else:
self.ipdb.seek(-1, 1)
return self.getString(offset)
def getAddr(self, offset, ip=0):
self.ipdb.seek(offset + 4)
countryAddr = ""
areaAddr = ""
str = self.ipdb.read(1)
(byte,) = struct.unpack('B', str)
if byte == 0x01:
countryOffset = self.getLong3()
self.ipdb.seek(countryOffset)
str = self.ipdb.read(1)
(b,) = struct.unpack('B', str)
if b == 0x02:
countryAddr = self.getString(self.getLong3())
self.ipdb.seek(countryOffset + 4)
else:
countryAddr = self.getString(countryOffset)
areaAddr = self.getAreaAddr()
elif byte == 0x02:
countryAddr = self.getString(self.getLong3())
areaAddr = self.getAreaAddr(offset + 8)
else:
countryAddr = self.getString(offset + 4)
areaAddr = self.getAreaAddr()
return countryAddr + " " + areaAddr
def dump(self, first , last):
if last > self.indexCount :
last = self.indexCount
for index in range(first, last):
offset = self.firstIndex + index * 7
self.ipdb.seek(offset)
buf = self.ipdb.read(7)
(ip, of1, of2) = struct.unpack("IHB", buf)
address = self.getAddr(of1 + (of2 << 16))
# 把GBK转为utf-8
address = unicode(address, 'gbk').encode("utf-8")
print "%d\t%s\t%s" % (index, self.ip2str(ip), address)
def setIpRange(self, index):
offset = self.firstIndex + index * 7
self.ipdb.seek(offset)
buf = self.ipdb.read(7)
(self.curStartIp, of1, of2) = struct.unpack("IHB", buf)
self.curEndIpOffset = of1 + (of2 << 16)
self.ipdb.seek(self.curEndIpOffset)
buf = self.ipdb.read(4)
(self.curEndIp,) = struct.unpack("I", buf)
def getIpAddr(self, ip):
L = 0
R = self.indexCount - 1
while L < R-1:
M = (L + R) / 2
self.setIpRange(M)
if ip == self.curStartIp:
L = M
break
if ip > self.curStartIp:
L = M
else:
R = M
self.setIpRange(L)
# version information, 255.255.255.X, urgy but useful
if ip & 0xffffff00L == 0xffffff00L:
self.setIpRange(R)
if self.curStartIp <= ip <= self.curEndIp:
address = self.getAddr(self.curEndIpOffset)
# 把GBK转为utf-8
address = unicode(address, 'gbk')
else:
address = u"未找到该IP的地址"
return address
def getIpRange(self, ip):
self.getIpAddr(ip)
range = self.ip2str(self.curStartIp) + ' - ' \
+ self.ip2str(self.curEndIp)
return range
def getString(self, offset = 0):
if offset :
self.ipdb.seek(offset)
str = ""
ch = self.ipdb.read(1)
(byte,) = struct.unpack('B', ch)
while byte != 0:
str += ch
ch = self.ipdb.read(1)
(byte,) = struct.unpack('B', ch)
return str
def ip2str(self, ip):
return str(ip >> 24)+'.'+str((ip >> 16) & 0xffL)+'.'+str((ip >> 8) & 0xffL)+'.'+str(ip & 0xffL)
def str2ip(self, s):
(ip,) = struct.unpack('I', socket.inet_aton(s))
return ((ip >> 24) & 0xffL) | ((ip & 0xffL) << 24) | ((ip >> 8) & 0xff00L) | ((ip & 0xff00L) << 8)
def getLong3(self, offset=0):
if offset:
self.ipdb.seek(offset)
str = self.ipdb.read(3)
(a, b) = struct.unpack('HB', str)
return (b << 16) + a
最后看一下validator.py,由于使用的是python2.7,所以要使用协程采用了gevent:
#coding:utf-8
import datetime
from gevent.pool import Pool
import requests
import time
from config import TEST_URL
import config
from db.SQLiteHelper import SqliteHelper
from gevent import monkey
monkey.patch_all()
__author__ = 'Xaxdus'
class Validator(object):
def __init__(self):
self.detect_pool = Pool(config.THREADNUM)
def __init__(self,sqlHelper):
self.detect_pool = Pool(config.THREADNUM)
self.sqlHelper =sqlHelper
def run_db(self):
'''
从数据库中检测
:return:
'''
try:
#首先将超时的全部删除
self.deleteOld()
#接着将重复的删除掉
#接着检测剩余的ip,是否可用
results = self.sqlHelper.selectAll()
self.detect_pool.map(self.detect_db,results)
return self.sqlHelper.selectCount()#返回最终的数量
except Exception,e:
print e
return 0
def run_list(self,results):
'''
这个是先不进入数据库,直接从集合中删除
:param results:
:return:
'''
# proxys=[]
# for result in results:
proxys = self.detect_pool.map(self.detect_list,results)
#这个时候proxys的格式是[{},{},{},{},{}]
return proxys
def deleteOld(self):
'''
删除旧的数据
:return:
'''
condition = "updatetime<'%s'"%((datetime.datetime.now() - datetime.timedelta(minutes=config.MAXTIME)).strftime('%Y-%m-%d %H:%M:%S'))
self.sqlHelper.delete(SqliteHelper.tableName,condition)
def detect_db(self,result):
'''
:param result: 从数据库中检测
:return:
'''
ip = result[0]
port = str(result[1])
proxies={"http": "http://%s:%s"%(ip,port)}
start = time.time()
try:
r = requests.get(url=TEST_URL,headers=config.HEADER,timeout=config.TIMEOUT,proxies=proxies)
if not r.ok:
condition = "ip='"+ip+"' AND "+'port='+port
print 'fail ip =%s'%ip
self.sqlHelper.delete(SqliteHelper.tableName,condition)
else:
speed = round(time.time()-start, 2)
self.sqlHelper.update(SqliteHelper.tableName,'SET speed=? WHERE ip=? AND port=?',(speed,ip,port))
print 'success ip =%s,speed=%s'%(ip,speed)
except Exception,e:
condition = "ip='"+ip+"' AND "+'port='+port
print 'fail ip =%s'%ip
self.sqlHelper.delete(SqliteHelper.tableName,condition)
def detect_list(self,proxy):
'''
:param proxy: ip字典
:return:
'''
# for proxy in proxys:
ip = proxy['ip']
port = proxy['port']
proxies={"http": "http://%s:%s"%(ip,port)}
start = time.time()
try:
r = requests.get(url=TEST_URL,headers=config.HEADER,timeout=config.TIMEOUT,proxies=proxies)
if not r.ok:
print 'fail ip =%s'%ip
proxy = None
else:
speed = round(time.time()-start,2)
print 'success ip =%s,speed=%s'%(ip,speed)
proxy['speed']=speed
# return proxy
except Exception,e:
print 'fail ip =%s'%ip
proxy = None
return proxy
# return proxys
if __name__=='__main__':
# v = Validator()
# results=[{'ip':'192.168.1.1','port':80}]*10
# results = v.run(results)
# print results
pass
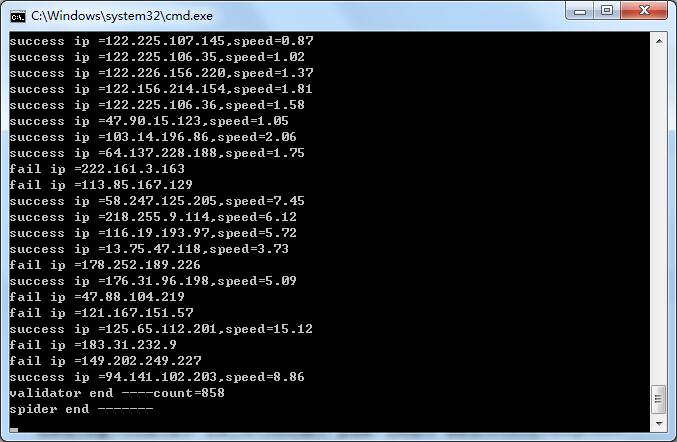
最后咱们看一下运行效果: 切换到工程目录下,cmd中执行python IPProxys.py:
这个时候咱们在浏览器中输入请求,就会返回响应的结果:
执行流程是每隔半小时检测一下数据库中ip地址的有效性,删除无效的代理ip。如果ip地址数量少于一个数值,爬虫将会启动,进行新一轮的爬取。当然检测时间和数据量都可以在config.py中配置。咱们看一下config.py的部分代码,大家就明白了:
'''
数据库的配置
'''
DB_CONFIG={
'dbType':'sqlite',#sqlite,mysql,mongodb
'dbPath':'./data/proxy.db',#这个仅仅对sqlite有效
'dbUser':'',#用户名
'dbPass':'',#密码
'dbName':''#数据库名称
}
CHINA_AREA=[u'河北',u'山东',u'辽宁',u'黑龙江',u'吉林'
,u'甘肃',u'青海',u'河南',u'江苏',u'湖北',u'湖南',
u'江西',u'浙江',u'广东',u'云南',u'福建',
u'台湾',u'海南',u'山西',u'四川',u'陕西',
u'贵州',u'安徽',u'重庆',u'北京',u'上海',u'天津',u'广西',u'内蒙',u'西藏',u'新疆',u'宁夏',u'香港',u'澳门']
QQWRY_PATH="./data/qqwry.dat"
THREADNUM = 20
API_PORT=8000
'''
爬虫爬取和检测ip的设置条件
不需要检测ip是否已经存在,因为会定时清理
'''
UPDATE_TIME=30*60#每半个小时检测一次是否有代理ip失效
MINNUM = 500 #当有效的ip值小于一个时 需要启动爬虫进行爬取
MAXTIME = 24*60 #当爬取存储开始一直使用的最大时间,如果超过这个时间,都删除
TIMEOUT = 5#socket延时
'''
反爬虫的设置
'''
'''
重试次数
'''
RETRY_TIME=3
'''
USER_AGENTS 随机头信息
'''
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
HEADER = {
'User-Agent': random.choice(USER_AGENTS),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Connection': 'keep-alive',
'Accept-Encoding': 'gzip, deflate',
}
TEST_URL='http://www.ip138.com/'
整个项目的代码很简单,大家如果想深入了解的话,就详细的看一下我的这个开源项目IPProxys代码,代码写的有点粗糙,日后再继续优化。
相关文章内容简介
1 免费代理IP能用于爬虫吗
免费代理IP能用于爬虫吗?免费代理IP就是不需要花钱,在网络上可以直接提取,然后用来替换IP。并不是所有项目都能用免费代理IP的,例如爬虫就不可以。 免费代理IP的来源比较杂,很多没有用,使用时间短,匿名程度也参差不齐,其中有一些是高度匿名的,但数量有限,也很难挑选。而爬虫工作需要的IP,要求比较高,因为爬虫IP一旦质量不高就会被对方网站发现,被禁止抓取数据,无法完成工作。所以,免费代理IP是不适合爬虫的。但如果免费代理IP的匿名程度够的话,使用效率低,也是符合使用需求的。 爬虫大家都知道,是采集数据的方式。通过采集来的数据分析,可以获取有价值的信息。而代理IP是换IP最方便的工具,爬虫工作是要用代理IP的。 爬虫对被爬的网站来说是毫无利益的,反而会影响到服务器的工作,所以现在都设有反爬程序,IP限制是最基本的。爬虫工作的时候,如果速度快,用同一个IP会有访问的问题,这时网络就会有验证或者直接封锁IP,给爬虫工作带来了很大的困难。 ... [阅读全文]
2 发帖用代理IP有什么好处?
发帖用代理IP有什么好处?发帖是网络营销的主要途径,在发帖的时候,很多时候都要用到代理IP,这并不奇怪,代理IP给网络营销人员带来了很大的便利。那么,发帖用代理IP有什么好处? 贴吧大家都不陌生,很多人在贴吧交流,一般同一个IP只能发布有限的帖子,评论也是有限制的。如果想大量发帖,就需要用代理IP来解决了。有很多热帖有的是真实评论,有的可能需要代理IP来帮忙,用代理IP去访问网站,用户不会被网站监视限制,或者被封锁了。 随着网络的发展,网络营销是很多公司必须要做的,其中网络影响最重要的途径就是发帖。很多发帖的工作人员都在使用代理IP,但还有很多人并不了解。那么,营销发帖一定要用代理IP吗? 例如贴吧、微博等平台,这些平台发帖可以与其他网友进行交流,起到宣传的作用。但一个IP发帖的数量是有限的,如果想大量发帖,就需要代理IP的帮助。更换IP后,就可以伪装成一个全新的用户,自然不会被平台限制。还有网络营销最常见的问答方式,也需要更换IP后进行自问... [阅读全文]
推荐阅读
27
2021-01
水滴如何正确的选择动态代理IP?
在我们生活中,代理IP的使用范围是很广泛的,对于动态代理IP来说,是指用户在上网的时候动态化分配的IP,那么大家知道如何正确的选择动态代理IP吗?下面就给大家详细介绍下动态代理IP的
14
2020-09
选择代理IP如何对比?
随着互联网的市场需求需求,使用代理IP也是越发广泛,随便找个搜索引擎输入代理相关的关键词,就会有很多供应商,没有成千也有几百的展示,那么对于一个需求者,应该如何区挑选和对比
10
2020-03
免费代理IP最大的问题在哪?
很多朋友很气愤的问我,你家的免费代理IP要怎么使用才可以,为什么我浏览器设置了代理后上不了网了,我试了好多个都是这样,你家的都是假IP吗?让我哭笑不得,我只好耐心跟她解释:为
28
2020-10
使用代理ip对本地网络有什么要求?
现如今互联网时代,基本是家家户户都会安装宽带,家庭电视,手机wifi都离不开网络了,工作上就更不用说,都是线上工作,更离不开网络,但宽带运营商有很多家,除了电信,联通,移动三
25
2020-12
爬虫反爬机制会出现哪几种情况?
爬虫是我们从事大数据没有几个工作者不接触的,那么使用爬虫必然就要用到代理ip来解决反爬虫机制,我们在获取目标网站的网页数据信息时,必定会遭受到对方服务器的反爬机制所困恼。
31
2020-08
大数据时代离不开网络爬虫
数据时代的来临,传统行业和新兴行业在运营模式上面临着各种各样改革创新的问题。因为互联网发展迅速,给原本的产业和收益模式都带来了更多的可能性。为了顺应时代发展,并且能够在改
热门文章
因为专业! 所以简单! 产品至上,价格实惠 是我们服务追求的宗旨
免费试用